MMFuser: Multimodal Multi-Layer Feature Fuser for Fine-Grained Vision-Language Understanding
Oct 15, 2024· ,,,,,,·
1 min read
,,,,,,·
1 min read
Yue Cao
Yangzhou Liu
Zhe Chen
Guangchen Shi
Wenhai Wang
Danhuai Zhao
Tong Lu
Abstract
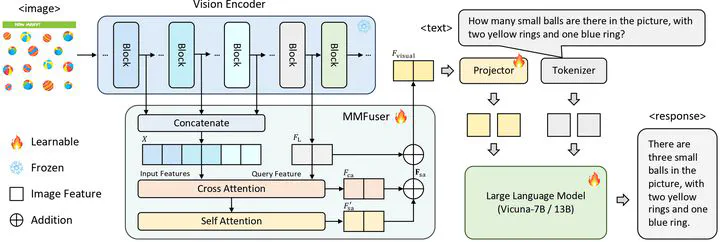
Despite significant advancements in Multimodal Large Language Models (MLLMs) for understanding complex human intentions through cross-modal interactions, capturing intricate image details remains challenging. Previous methods integrating multiple vision encoders to enhance visual detail introduce redundancy and computational overhead. We observe that most MLLMs utilize only the last-layer feature map of the vision encoder for visual representation, neglecting the rich fine-grained information in shallow feature maps. To address this issue, we propose \modelname, a simple yet effective multi-layer feature fuser that efficiently integrates deep and shallow features from Vision Transformers (ViTs). Specifically, it leverages semantically aligned deep features as queries to dynamically extract missing details from shallow features, thus preserving semantic alignment while enriching the representation with fine-grained information. Applied to the LLaVA-1.5 model, \modelname~achieves significant improvements in visual representation and benchmark performance, providing a more flexible and lightweight solution compared to multi-encoder ensemble methods. The code and model have been released at https://github.com/yuecao0119/MMFuser.
Type
Citation
If you find this project useful in your research, please consider cite:
@article{cao2024mmfuser,
title={Mmfuser: Multimodal multi-layer feature fuser for fine-grained vision-language understanding},
author={Cao, Yue and Liu, Yangzhou and Chen, Zhe and Shi, Guangchen and Wang, Wenhai and Zhao, Danhuai and Lu, Tong},
journal={arXiv preprint arXiv:2410.11829},
year={2024}
}
{kind=link}