Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
Dec 6, 2024·, ,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,·
1 min read
,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,·
1 min read
Zhe Chen
Weiyun Wang
Yue Cao
Yangzhou Liu
Zhangwei Gao
Erfei Cui
Jinguo Zhu
Shenglong Ye
Hao Tian
Zhaoyang Liu
Lixin Gu
Xuehui Wang
Qingyun Li
Yimin Ren
Zixuan Chen
Jiapeng Luo
Jiahao Wang
Tan Jiang
Bo Wang
Conghui He
Botian Shi
Xingcheng Zhang
Han Lv
Yi Wang
Wenqi Shao
Pei Chu
Zhongying Tu
Tong He
Zhiyong Wu
Huipeng Deng
Jiaye Ge
Kai Chen
Kaipeng Zhang
Limin Wang
Min Dou
Lewei Lu
Xizhou Zhu
Tong Lu
Dahua Lin
Yu Qiao
Jifeng Dai
Wenhai Wang
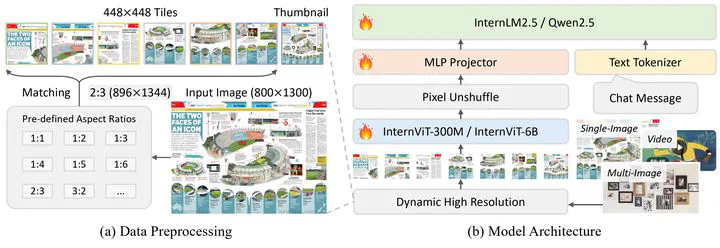 Overall architecture.
Overall architecture.Abstract
We introduce InternVL 2.5, an advanced multimodal large language model (MLLM) series that builds upon InternVL 2.0, maintaining its core model architecture while introducing significant enhancements in training and testing strategies as well as data quality. In this work, we delve into the relationship between model scaling and performance, systematically exploring the performance trends in vision encoders, language models, dataset sizes, and test-time configurations. Through extensive evaluations on a wide range of benchmarks, including multi-discipline reasoning, document understanding, multi-image / video understanding, real-world comprehension, multimodal hallucination detection, visual grounding, multilingual capabilities, and pure language processing, InternVL 2.5 exhibits competitive performance, rivaling leading commercial models such as GPT-4o and Claude-3.5-Sonnet. Notably, our model is the first open-source MLLMs to surpass 70% on the MMMU benchmark, achieving a 3.7-point improvement through Chain-of-Thought (CoT) reasoning and showcasing strong potential for test-time scaling. We hope this model contributes to the open-source community by setting new standards for developing and applying multimodal AI systems. HuggingFace demo see https://huggingface.co/spaces/OpenGVLab/InternVL.
Type
Citation
If you find this project useful in your research, please consider cite:
@article{chen2024expanding,
title={Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
{kind=link}